OCR is not the same as document understanding. Conflating the two leads to pipelines that fail silently in production often on the exact documents that matter most.
What Azure Document Intelligence’s OCR Actually Does
Azure Document Intelligence is an outstanding service, but it is important to be precise about what its core OCR engine does: it identifies and transcribes machine-printed and handwritten text from document images. It converts pixels to structured text with bounding box coordinates and confidence scores.
What it does not do natively:
- Understand document intent or semantics
- Reliably detect handwritten signatures as signatures (vs. handwritten text)
- Handle complex, unstructured layouts that deviate from trained templates
- Reason about the relationship between fields across a multi-page document
A handwritten signature is, to an OCR engine, just handwriting it cannot transcribe. It may return low-confidence text, a blank, or noise — but it will not tell you ‘this is a signature’.
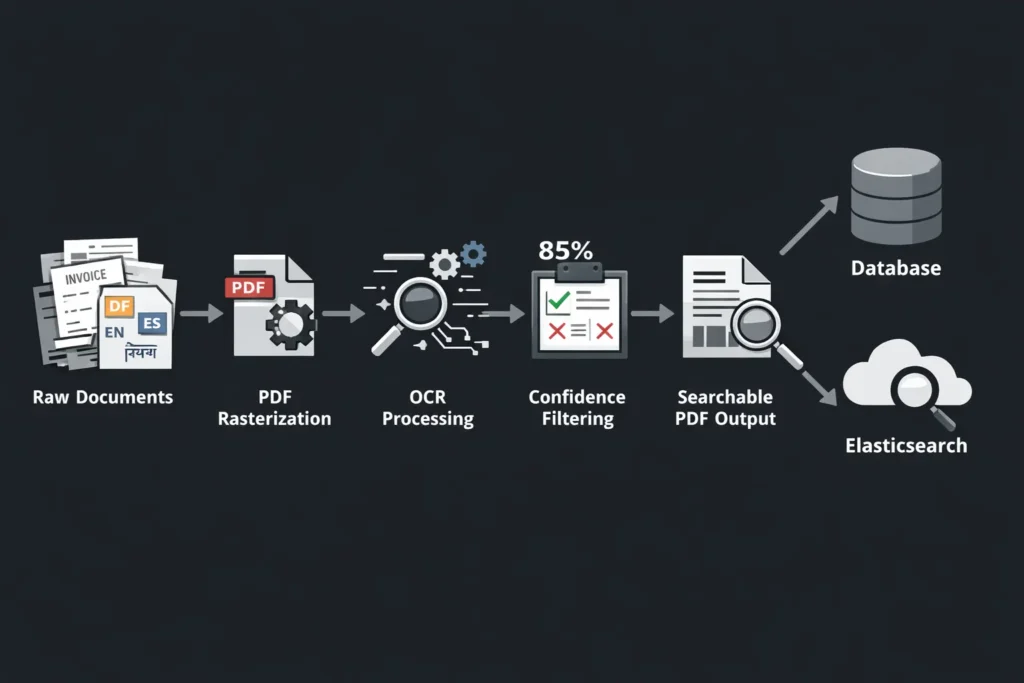
How to build an Enterprise OCR Pipeline in .Net
The Handwritten Signature Problem
This is one of the most common gotchas in document processing pipelines, particularly for legal and compliance documents like engagement letters, contracts, and consent forms.
Azure Document Intelligence’s prebuilt and custom neural models are trained on field extraction — dates, names, addresses, checkboxes. A signature block is fundamentally different: it is a visual attestation, not a text field. The model was not trained to classify visual regions as ‘signed vs. unsigned’.
What actually happens when Document Intelligence encounters a signature:
- The OCR layer may transcribe scribbles as garbled characters
- The field extraction layer returns null or an empty string for the signature field
- Confidence scores are low, but the pipeline treats low-confidence as ‘present but uncertain’ rather than ‘missing’
- The document is marked as processed with no downstream alert that a required field is absent
This silent failure mode is dangerous in compliance contexts. A document that should be rejected for missing signatures passes through your pipeline as complete.
Structured vs. Unstructured Layouts
Document Intelligence custom neural models perform very well on known, consistent templates — tax forms, invoices, purchase orders. The model learns the spatial layout and knows where field values appear relative to their labels.
Problems emerge with:
- Engagement letters and contracts where signature blocks may appear anywhere on variable-length final pages
- Scanned PDFs with skew, blur, or low DPI (below 150 DPI significantly degrades accuracy)
- Documents that mix handwritten annotations with printed text
- Multi-column layouts where reading order breaks across columns
The model’s spatial assumptions trained on your labeled dataset break the moment a vendor sends a slightly different template version.
Confidence Scores Are Not What You Think
Document Intelligence returns confidence scores per extracted field. A common mistake is treating any non-null, non-zero confidence value as a valid extraction.
A confidence of 0.45 on a signature field does not mean the signature is there with 45% confidence. It means the model found something in that region but is uncertain what it is.
Production-ready pipelines need explicit confidence thresholds and field-specific handling:
- Fields below threshold → route to human review queue, not automatic processing
- Null extractions on required fields → hard rejection, not silent pass-through
- Signature fields → treat null as failed, regardless of overall document confidence
DPI, Scan Quality, and Pre-processing
Raw document scans are often not OCR-ready. Common quality issues and their impact:
- Below 150 DPI: significant character recognition errors, especially on small fonts
- Skew above 5 degrees: reading order breaks, multi-column documents misparse
- JPEG compression artifacts: characters blur together, punctuation is lost
- Low contrast (faded ink): confidence scores drop uniformly, high false-null rate
Pre-processing with tools like OpenCV for deskewing, contrast normalization, and resolution upscaling before sending to Document Intelligence can recover 10-20% accuracy on poor-quality scans.
When to Reach Beyond OCR
Some document understanding tasks are fundamentally beyond what OCR-based models can solve:
- Signature presence/absence detection → use a vision model or Azure Content Understanding
- Reasoning about clause relationships across pages → use an LLM with document grounding
- Zero-shot handling of new document types → use Azure Content Understanding (GA 2025-11-01)
- Visual layout classification (is this a cover page? a signature page?) → multi-modal model
The right architecture uses Document Intelligence where it excels (field extraction from known templates) and supplements it with generative AI capabilities where OCR falls short.
Practical Checklist Before Going to Production
- Define explicit confidence thresholds per field type — do not use a single global threshold
- Test on the worst 10% of your document sample — skewed, low-DPI, mixed handwriting
- Implement a human review queue for low-confidence and null extractions on required fields
- Validate signature fields separately from text fields
- Monitor extraction confidence distributions in production, not just pass/fail rates
- Plan for template drift — when vendors change their forms, your model needs retraining
Key Takeaways
- OCR transcribes text — it does not understand documents or detect signatures
- Silent failures on signature fields are the most dangerous failure mode in compliance pipelines
- Confidence scores require field-specific thresholds and human review workflows
- Poor scan quality is a pre-processing problem, not a model problem fix it upstream
- Complement Document Intelligence with vision-capable models for tasks outside its design scope
Learn More At
https://www.signzy.com/blogs/ocr-pipeline-built-using-deep-learning